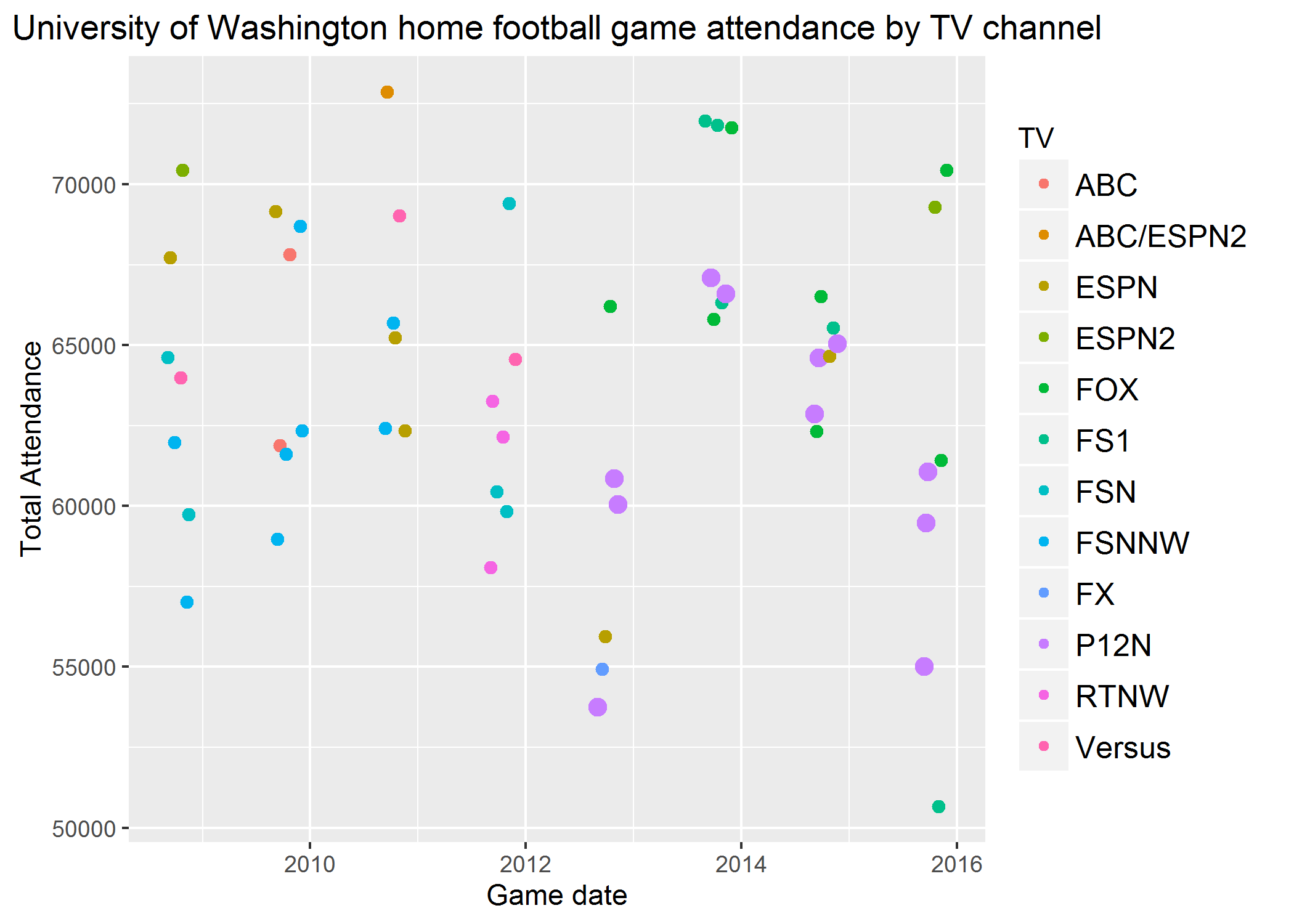
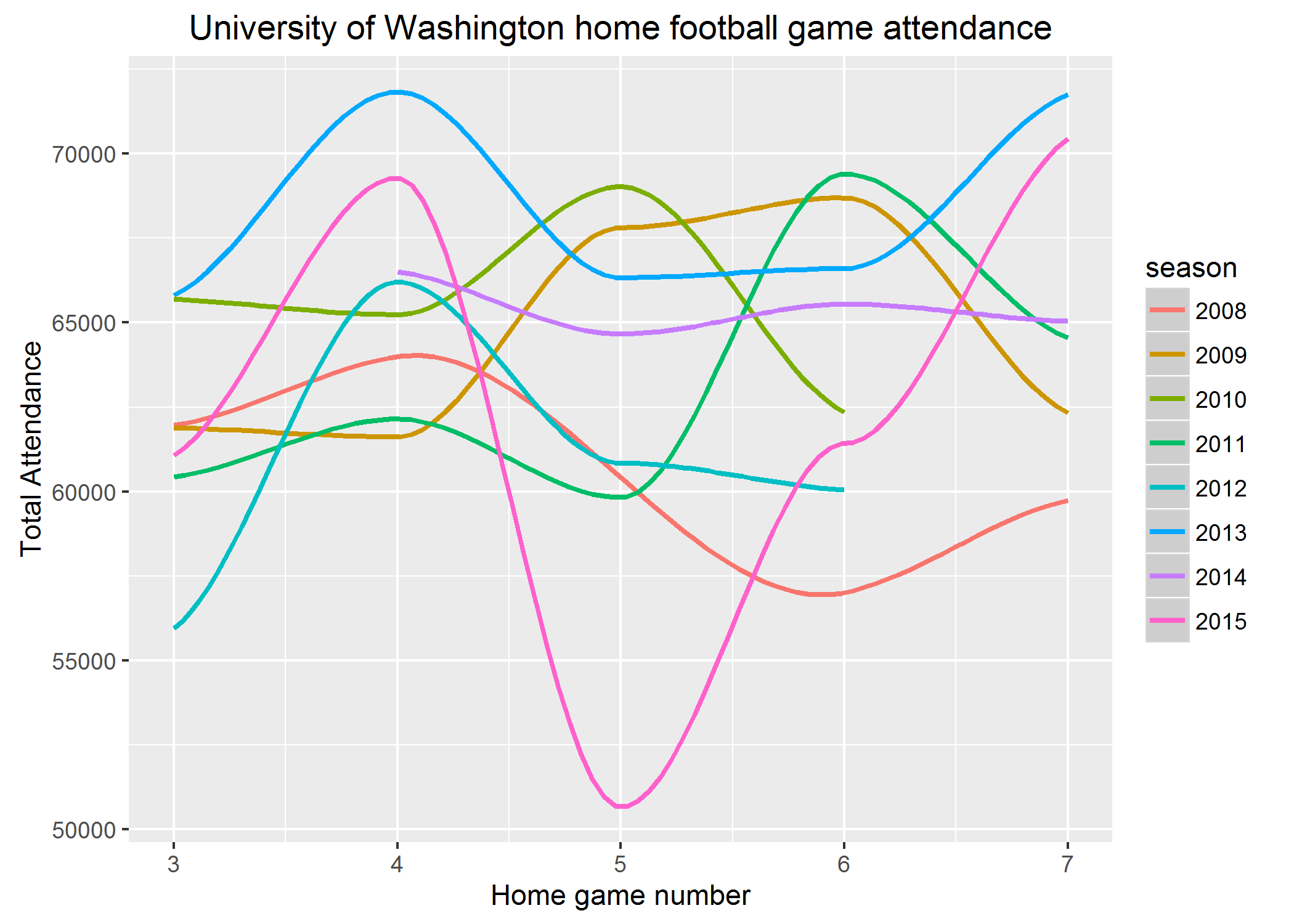
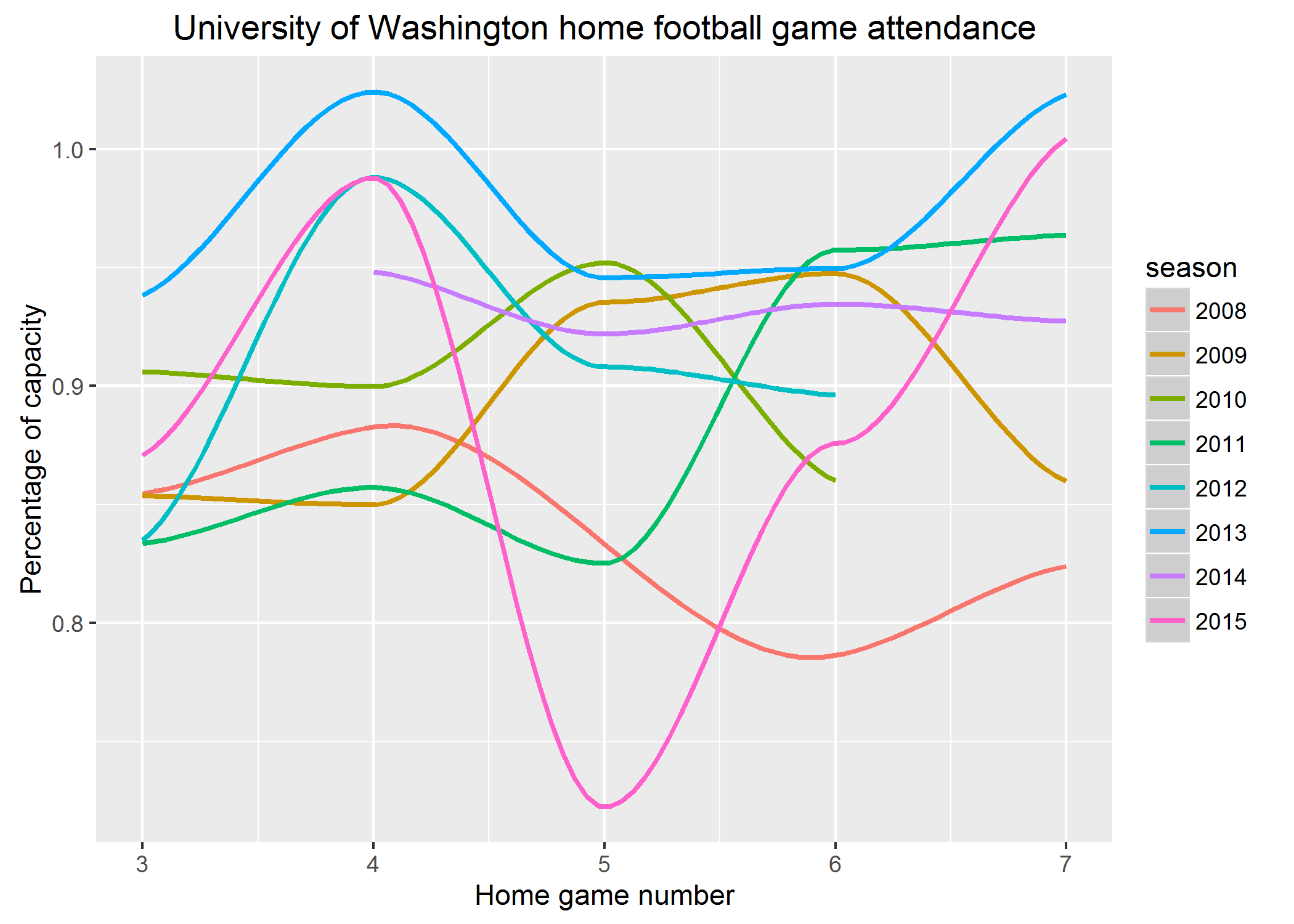
Smarter Binge Watching With Linear Regression
I am not much of a binge watcher but I do enjoy quality TV shows which is why I think GraphTV is so great. GraphTV plots the IMDb user ratings for every episode and then performs a linear regression of the episode rating by the episode number to create a trend line which helps you see if the show gets better or worse over the course of the season.
This is nice but it can get difficult to use GraphTV for shows like Golden Girls and downright impossible for shows like The Simpsons.
To solve this I created a GitHub repo binge-trendy. Because the trend line is fit to the IMDb user rating data, we are interested in which episodes do IMDb users think are better than the regression model predicts which translates to any deviation from the trend line. Since I am only interested in episodes that are rated higher than the regression model would have predicted, I only look at episodes with a positive residual.
For example, Golden Girls season 4
| Season | Episode | Name |
|---|---|---|
| 4 | 1 | Yes, We Have No Havanas |
| 4 | 2 | The Days and Nights of Sophia Petrillo |
| 4 | 6 | Sophia’s Wedding: Part 1 |
| 4 | 9 | Scared Straight |
| 4 | 11 | The Auction |
| 4 | 14 | Love Me Tender |
| 4 | 15 | Valentine’s Day |
| 4 | 19 | Till Death Do We Volley |
| 4 | 20 | High Anxiety |
| 4 | 22 | Sophia’s Choice |
| 4 | 23 | Rites of Spring |
| 4 | 24 | Foreign Exchange |
I realize the code is not great, pylint currently gives it a 6.05 but if there is one thing I have learned in software:
The only way to write good code is to write tons of shitty code first. Feeling shame about bad code stops you from getting to good code
— Hadley Wickham (@hadleywickham) April 17, 2015