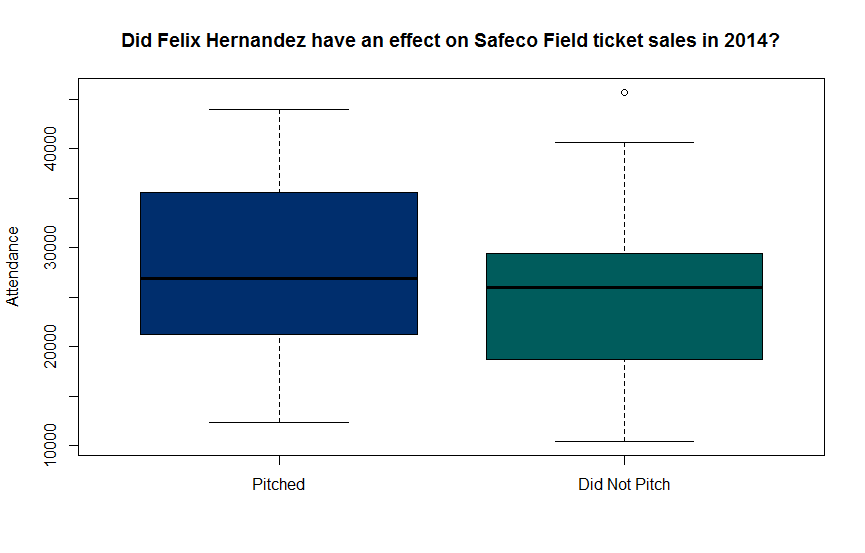
Batch Collection of Park Boundaries With Open Street Map
Open Street Map (OSM) is, simply put, a freely available and editable map of the world. I have been interested in improving the availability of boundaries in Seattle and wanted to add park boundaries to this list as well. It was easy to look up boundaries on OSM, for example Salmon Bay Park shows the various nodes that make up its boundaries. But I had struggled with how to automate this search since at last count Seattle had over 400 parks. After months of struggling with the OSM API, I fortuitously stumbed across the following tweet:
Two
map data posts:
Historic map warping for @somethingmodern http://t.co/7POw8PNBXI
Data
from OSM for @alignedleft
http://t.co/DqxAuyPunh
—
Michal Migurski (@michalmigurski) August
15, 2015This tweet lead me to Mapzen which provides a service called Metro Extracts which provides datasets from OSM on a weekly basis. I downloaded the OSM2PGSQL GeoJSON file for Seattle which provided me files for Line, Point, and Polygon geometries. I then used ogr2ogr to filter for parks only with the command
ogr2ogr select 'osm_id, name, geometry' where "leisure = 'park'"
This produced a GeoJSON file that looked like this:
Obviously, more filtering needed to be done. Since many of these parks were not in Seattle, I used the Nominatim API to search for each park based on the OSM ID number. For example, the above mentioned park Salmon Bay Park returns a nicely formatted XML file which I just filtered based on city.
Even after this there were still parks that were wrongly labelled as being in Seattle. I loaded the file into R and subset based on OSM ID and then used rgdal to write the final result out as a GeoJSON file.
The take home lesson for me is that OSM is an excellent service but as with any publically annotated dataset be prepared to invest some time into cleaning and validating the data.