The Listserve is an email lottery, you sign up and once a day someone
gets a chance to send the entire list an email. My previous
post
covered how I fetched these emails, this post will discuss the actual
statistics obtained from The Listserve emails.
To:
The Listserve website mentions the countries of subscribers but thats
about it. As of today, there are currently 21,402 subscribers. I
fetched all the archival data I could from Internet Archive and looked
at enrollment over time which has stayed consistent around 20,000. I
also plotted
enrollment over time.
From:
The Listserve allows you to use any name you want as the sender of the email, here are the ones that occurred more than once:
| Name |
Occurrence |
| Anonymous |
12 |
| Laura |
3 |
| The Listserve |
2 |
| Ben |
2 |
| Beth |
2 |
| David |
2 |
| Sam |
2 |
| Michelle Huang |
2 |
| T. |
2 |
Interesting that Michelle Huang had two entries, what happens if we look at first name only?
| Name |
Occurrence |
| Anonymous |
12 |
| Chris |
8 |
| David |
7 |
| Jordan |
4 |
| Michelle |
4 |
| Alex |
3 |
| Andy |
3 |
| Ben |
3 |
| Brian |
3 |
| Daniel |
3 |
| James |
3 |
| Laura |
3 |
What about time of day sent?
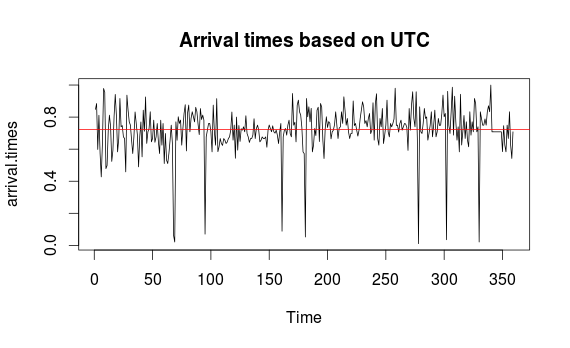
I took all the timestamps from the emails and plotted when they were
sent based on GMT. This was more due to personal curiosity but
interesting nonetheless. The red line in the plot is the mean time
which ended up being 17:19:15 GMT. Those large drops are likely due to
some nuances in email dates. For example, I got two emails on 23 June
2012 and none on 22 June.
Subject:
I took all the subject lines and created a word frequency table on how
often that word occurred:
| Word |
Occurrence |
| life |
9 |
| world |
9 |
| day |
8 |
| little |
8 |
| love |
7 |
| story |
7 |
| advice |
6 |
| time |
6 |
Body:
For the body of the email I created a Term-Document Matrix which is a matrix that describes the frequency of words and how often they occur together. This allows themes and trends of the body of work or corpus, which in this case happens to be The Listserve emails. I took all the emails and removed punctuation and stop words such as “and” or “but” and made a matrix based on how often the most common words occured together. I then created a dendrogram of all the words and how they clustered with each other.

The majority of the words are pretty evenly clustered and its difficult
to determine any trends. However there is a cluster on the far left
side of the tree which I zoomed in on:

This cluster includes word pairs such as “email” and “listserve”, “love” and “time”, and “life” and “people”. While its not surprising to see these words occurring so often together, it is interesting to see that a majority of people use this email to dispense wisdom or advice to the masses.
I have not yet been selected for The Listserve but I am sure these
findings here will strongly influence what I write. In the meantime,
I want to learn more about text processing since I found it pretty interesting.


{kind=link}